Open Source
Self-Hosted
Structure-Aware
Production-Ready
The "Set & Forget"
Data Pipeline for Enterprise RAG
Convert unstructured data into structured knowledge. Zero data egress. 100% Data Sovereignty.
Unified Pipeline
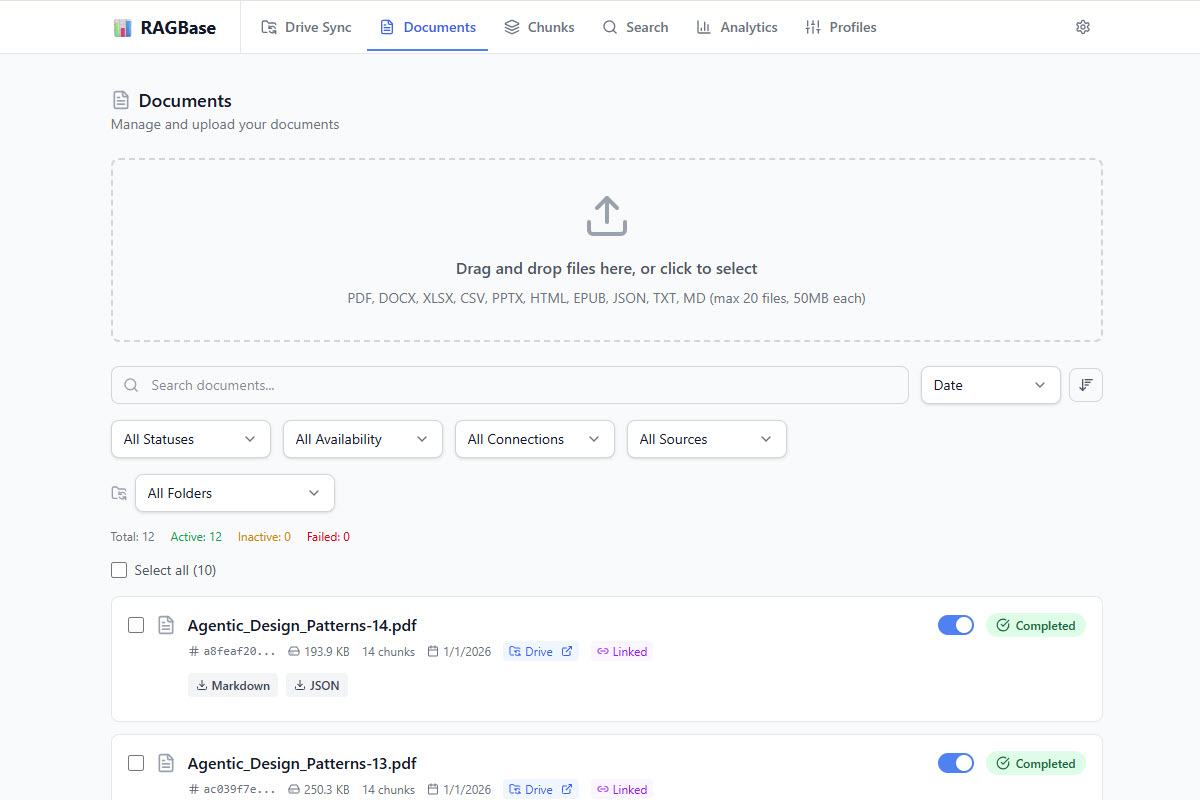
Process PDF, DOCX, PPTX, HTML, TXT, JSON and more through a single, robust AI worker pipeline.
Drive Sync
Auto-sync Google Drive folders with incremental updates. Works with OAuth for secure access.
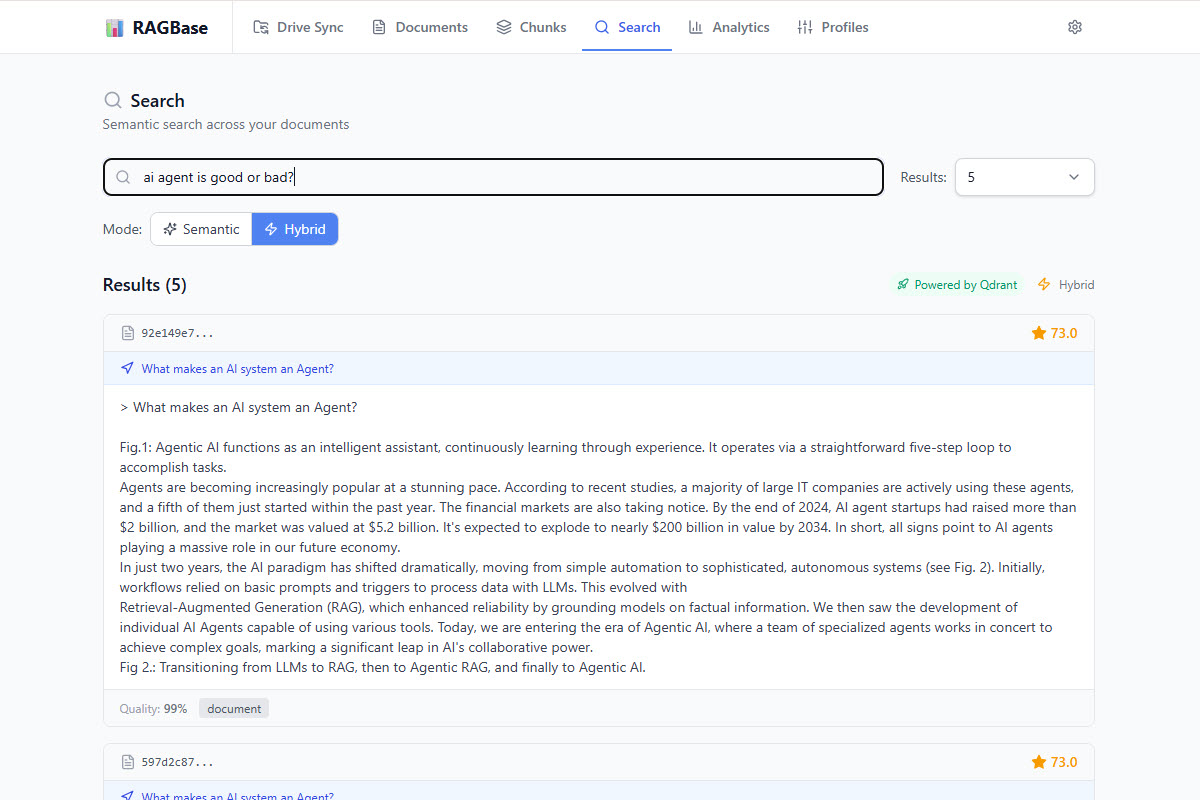
Hybrid Search
Advanced retrieval using Dense vectors + Sparse SPLADE vectors via Qdrant for superior accuracy.
Data Sovereignty
100% self-hosted via Docker. You own your infrastructure. No external API calls for data processing.
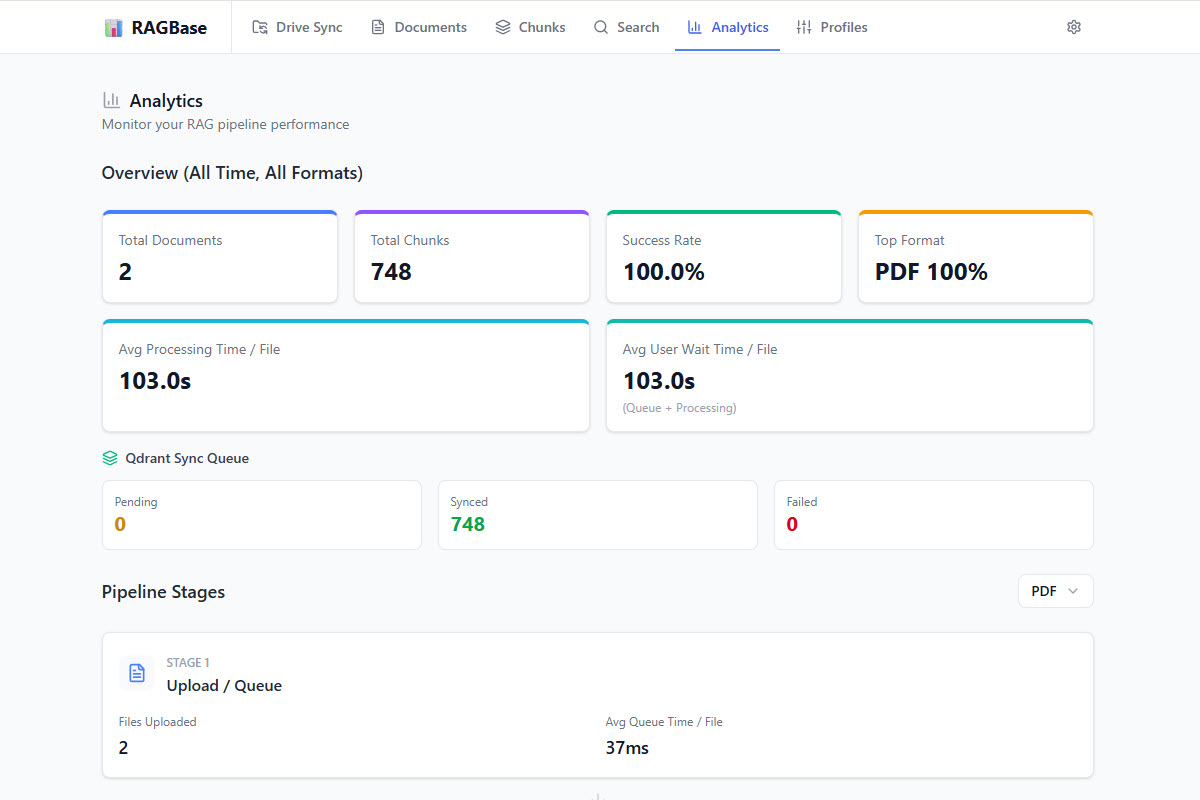
Production Ready
Built with TypeScript and Python. Includes structured logging, Prometheus metrics, and rate limiting.
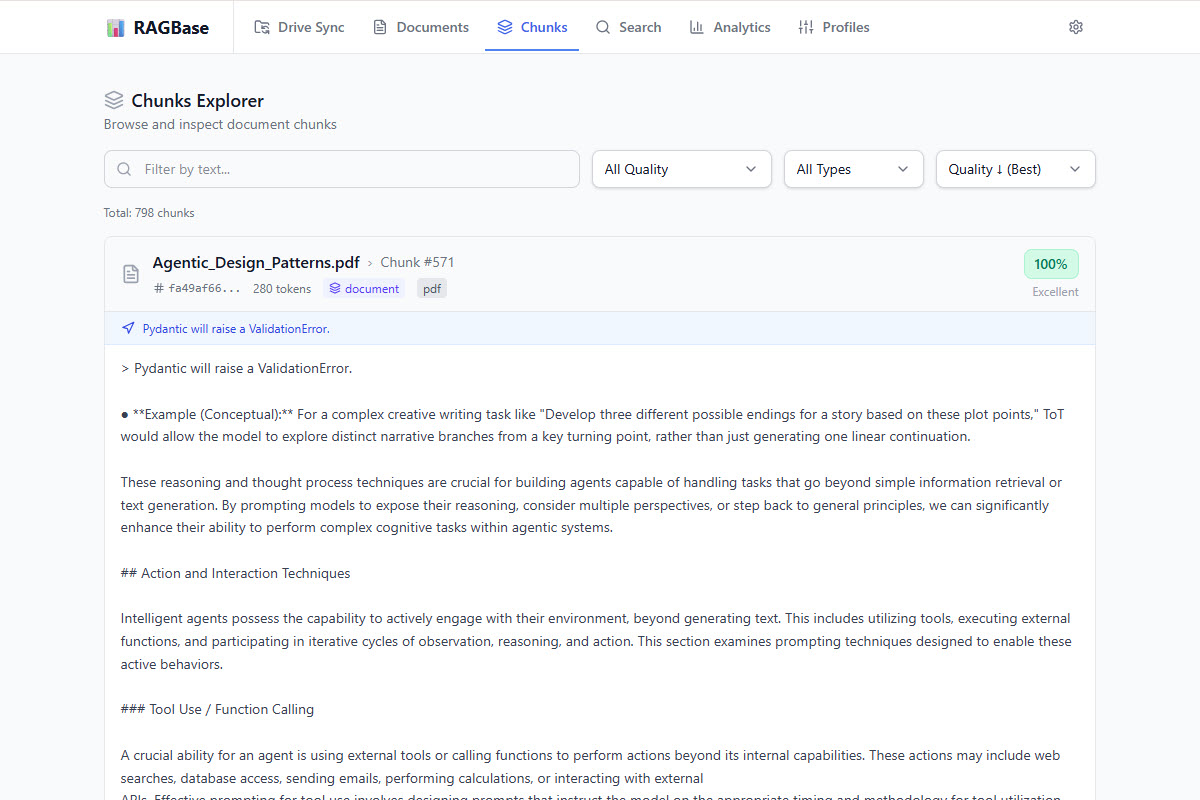
Quality Control
Automated analysis to flag poor content. Auto-fix pipeline merges short chunks and splits long ones.
Built With
Node.js
Fastify
Python
FastAPI
React
Tailwind
Qdrant
PostgreSQL
Redis